
二分查找
二分法是一种较为简单通用的搜索算法,但是在实际动手写时,却经常因为细节问题导致无法一次性写对,这里整理出了现代二分法的最佳实践写法,即红蓝染色/边界搜索算法,理解该方法后对于各种二分变种问题都能一次写对。
1 | """ |
C++20 std::ranges 中的 lower_bound、upper_bound 与 Python bisect 模块中的 bisect_left、bisect_right,这四个函数本质上都做同一件事:在一个已排序的序列中,使用二分查找算法来高效地找到一个合适的位置。它们的核心目的不是简单地“查找”一个元素是否存在,而是确定一个值应该被插入到序列的哪个位置,才能继续保持序列的有序性。
核心概念理解
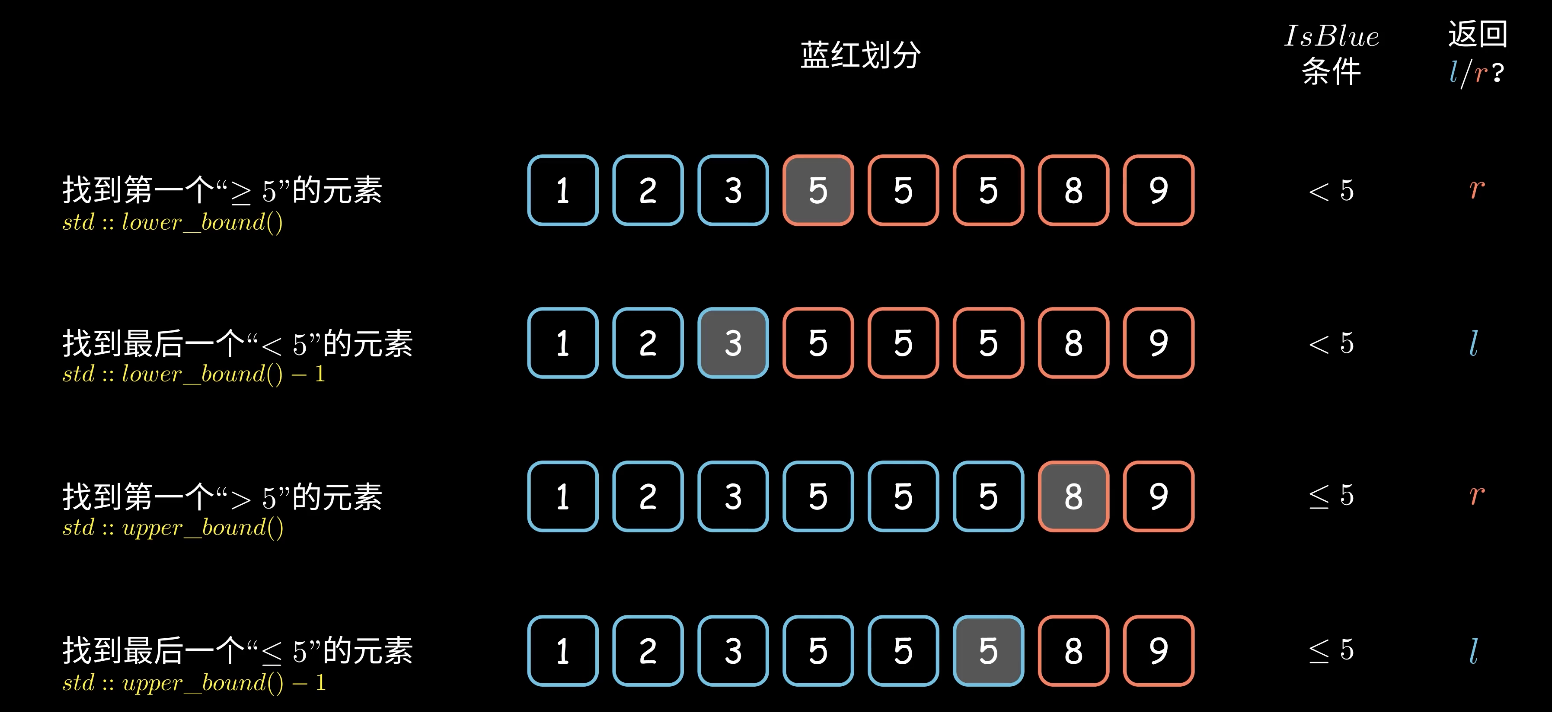
在深入细节之前,我们先统一理解两个核心概念:lower_bound(或 left)和 upper_bound(或 right)。
假设你有一个已排序的序列,比如 [10, 20, 30, 30, 30, 40, 50],现在你想查找值 30。
lower_bound/bisect_left(寻找下界/左边界)- 它会找到序列中第一个可以插入
30而不破坏排序的位置。 - 换句话说,它返回的是第一个不小于(大于或等于)
30的元素的位置。 - 在
[10, 20, **30**, 30, 30, 40, 50]中,这个位置是第一个30所在的位置(索引 2)。
- 它会找到序列中第一个可以插入
upper_bound/bisect_right(寻找上界/右边界)- 它会找到序列中最后一个可以插入
30而不破坏排序的位置。 - 换句话说,它返回的是第一个严格大于
30的元素的位置。 - 在
[10, 20, 30, 30, 30, **40**, 50]中,这个位置是40所在的位置(索引 5)。
- 它会找到序列中最后一个可以插入
一个关键的记忆技巧:
_left/lower_会把新元素插入到现有相同元素的左边。_right/upper_会把新元素插入到现有相同元素的右边。
第一部分:C++ std::ranges::lower_bound 和 std::ranges::upper_bound
这些是 C++20 ranges 库的一部分,相比于 C++17 及之前的 std::lower_bound,它们提供了更现代化、更简洁的接口。
前提条件:操作的范围(range)必须已经根据所用的比较操作排好序。
返回值:返回一个迭代器(iterator),指向找到的位置。如果找不到符合条件的位置(例如,查找的值比所有元素都大),则返回范围的 end() 迭代器。
1. std::ranges::lower_bound
签名 (简化版):
1 | template<forward_range R, class T, class Proj = identity, class Comp = ranges::less> |
R&& r: 一个范围,例如std::vector、std::array或std::string_view。const T& value: 要查找的值。Comp comp(可选): 自定义比较函数对象。默认是std::ranges::less,即<运算符。Proj proj(可选): 投影函数。在比较之前,会对范围中的每个元素应用这个函数。这是一个非常强大的功能。
详细解释:
它返回一个迭代器 it,指向范围 r 中第一个满足 !comp(proj(*it), value) 的元素。
如果使用默认的 comp (<) 和 proj (无操作),这个条件就等价于 !(*it < value),也就是 *it >= value。
代码示例:
1 |
|
2. std::ranges::upper_bound
签名 (与 lower_bound 类似):
1 | template<forward_range R, class T, class Proj = identity, class Comp = ranges::less> |
详细解释:
它返回一个迭代器 it,指向范围 r 中第一个满足 comp(value, proj(*it)) 的元素。
如果使用默认的 comp 和 proj,这个条件就等价于 value < *it,也就是 *it > value。
代码示例 (续上):
1 |
|
C++ 投影 (Projection) 的强大之处
假设你有一个结构体 Person 的 vector,并按年龄排序,你想查找特定年龄的人。
1 | struct Person { |
这里,&Person::age 是一个投影,它告诉 lower_bound:“在比较时,不要看整个 Person 对象,只看它的 age 成员。” 这使得代码非常干净和直观。
第二部分:Python bisect.bisect_left 和 bisect.bisect_right
这些函数位于 Python 标准库的 bisect 模块中。
前提条件:操作的列表(list)必须已经排好序。
返回值:返回一个整数索引(index),表示合适的插入点。这与 C++ 返回迭代器是主要区别之一。
1. bisect.bisect_left
签名:
1 | bisect.bisect_left(a, x, lo=0, hi=len(a)) |
a: 已排序的序列(通常是列表)。x: 要查找的值。lo,hi(可选): 指定在序列的哪个子切片中进行搜索。
详细解释:
功能上完全等同于 C++ 的 lower_bound。它返回一个插入点 i,这个插入点会将 x 插入到 a 中所有等于 x 的元素之前。
代码示例:
1 | import bisect |
2. bisect.bisect_right
签名 (与 bisect_left 类似):
1 | bisect.bisect_right(a, x, lo=0, hi=len(a)) |
bisect.bisect 是 bisect.bisect_right 的一个别名,两者完全相同。
详细解释:
功能上完全等同于 C++ 的 upper_bound。它返回一个插入点 i,这个插入点会将 x 插入到 a 中所有等于 x 的元素之后。
代码示例 (续上):
1 | import bisect |
注意:Python 的 bisect 模块本身没有 C++ ranges 那样直接的 key 或 projection 参数。如果你需要对复杂对象列表进行操作,通常有两种方法:
- 创建一个只包含用于排序的键的临时列表,然后用
bisect操作这个键列表。 - 将你的对象封装在一个类中,并实现
__lt__等比较方法,这样bisect就可以直接比较对象了。 - 从 Python 3.10 开始,
bisect函数新增了key参数,用法和sorted()的key类似,这使得它和 C++ 的投影功能对齐了。
核心差异与总结
| 特性 | C++ std::ranges |
Python bisect |
|---|---|---|
| 核心功能 | 查找排序序列中的插入点 | 查找排序序列中的插入点 |
lower_bound/_left |
返回第一个不小于目标值的位置 | 返回第一个不小于目标值的位置 |
upper_bound/_right |
返回第一个严格大于目标值的位置 | 返回第一个严格大于目标值的位置 |
| 返回值类型 | 迭代器 (Iterator) | 整数索引 (Integer Index) |
| 库/模块 | C++20 <ranges> 标准库 |
Python bisect 标准库模块 |
| 处理复杂对象 | 非常强大,通过**投影(projection)和自定义比较(comparator)**实现 | Python 3.10+ 支持 key 参数。之前版本需要额外处理。 |
| 语法 | std::ranges::func(range, value, comp, proj) |
bisect.func(list, value, lo, hi, key) |
常见应用场景
这些函数非常有用,远不止查找那么简单。
1. 高效地保持列表/向量有序
这是它们的本职工作。
- Python:
1
a.insert(bisect.bisect_left(a, x), x)
- C++:
1
v.insert(std::ranges::lower_bound(v, x), x);
2. 计算有序序列中特定值的数量
这是一个非常经典的用法。等于 value 的所有元素构成一个连续的区间,其起始点由 lower_bound 给出,结束点(不包含)由 upper_bound 给出。
- Python:
1
2count = bisect.bisect_right(a, 30) - bisect.bisect_left(a, 30)
# count = 5 - 2 = 3 - C++:
1
2
3auto count = std::distance(std::ranges::lower_bound(v, 30),
std::ranges::upper_bound(v, 30));
// count = 3
3. 检查元素是否存在
虽然有更直接的方法(如 std::ranges::binary_search 或 Python 的 in),但也可以用 lower_bound 来实现,这在某些复杂逻辑中可能更方便。
- Python:
1
2
3i = bisect.bisect_left(a, x)
if i != len(a) and a[i] == x:
print(f"{x} is in the list") - C++:这里必须检查
1
2
3
4auto it = std::ranges::lower_bound(v, x);
if (it != v.end() && *it == x) {
std::cout << x << " is in the vector" << std::endl;
}it != v.end(),因为如果x比所有元素都大,lower_bound会返回end(),解引用end()是未定义行为。
[1] 二分查找为什么总是写错?









